Spontaneous speech in Taiwan
When looking at published work on filled pauses and other disfluencies, it is nearly always implicit that researchers are looking at spontaneous speech. This makes sense -- so the explanation might go -- because under one characterization of disfluencies, they are used when one is trying to decide what to say next. And, indeed, it's no surprise that when one looks at studies of reading aloud, the number of filled pauses, for example, drops to a negligible number. But there is one context in which filled pauses may occur that is technically outside the realm of "spontaneous speech", but which I have seen almost no study of. That's what this news item is about.
But first, some travel context: I went to Academia Sinica in Taiwan to attend the Linguistic Patterns in Spontaneous Speech (LPSS) symposium, organized mainly by Shu-Chuan Tseng of the Linguistics Department there. LPSS has been a rather infrequent event, this being only the third iteration of it in something like 15 years. But it was a well-organized and very attractive event with a good slate of invited speakers and presentations.

Kelly Davis from Mozilla gave an excellent presentation on their open source project, Common Voice: Effectively a corpus of crowd-sourced speech samples from a wide variety of languages, and distributed under a Creative Commons open license. This is a fantastic resource with lots of potential, not only for those working in speech technology, but also for corpus linguists, as well as even language teaching practitioners like myself.
Another interesting presentation was by Satoshi Imaizumi from University of Tokyo Health Sciences who talked about his work with people who stutter in Japan. He talked about quite a lot of details of stuttering and it was great to hear of this from an active stuttering researcher. [Note: Believe it or not, there is not much crossover between research on pathological versus non-pathological disfluency. So, it's not often we get to hear from each other.] One interesting point he made was that stuttering adults who use filled pauses during their speech also tend to have lower measures of sweat on wrist (a typical measure of anxiety). He interprets this as their using filled pauses as a means of adjusting the timing of their speech and thereby keeping themselves calm, thereby minimizing the conditions in which a stuttering event is likely to occur. One wonders if all speakers may use filled pauses or other disfluencies in a similar way.
Several other researchers gave interesting presentations, too. My occasional collaborator, Michiko Watanabe gave a talk on Japanese filler types, comparing ee, anoo, and maa in informal speeches. Yasuharu Den talked about whether there really is a difference between naturally-occurring and laboratory-induced disfluencies, arguing that his data shows none (in Japanese), and Laurent Prevot gave a talk that somewhat mirrored my own (below) in which he talked about whether we could use movie subtitles to study linguistic patterns of spontaneous speech.
For my own presentation, I was focused specifically on what I call simulated disfluency. That is, the kind of disfluency that can be seen in film and TV dramatic performances, in which actors have a script to follow, have rehearsed their lines numerous times, yet display various forms of disfluency. For example, consider the filled pauses in the following extract from 12 Angry Men.
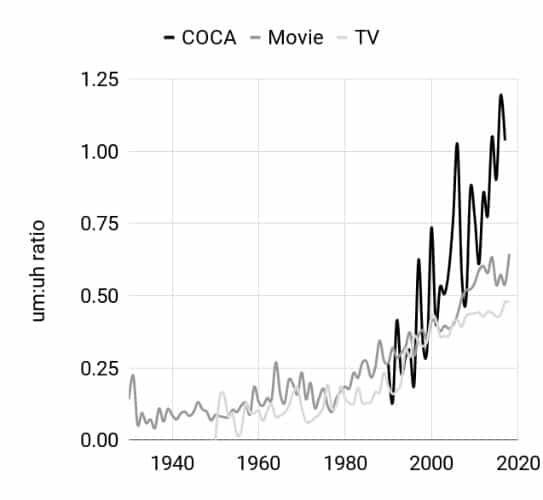
My interest was whether these disfluency patterns in transcripts of film and TV shows show a similar historical change that has been observed by Wieling et al 2016 and Fruehwald 2016 in which there is a trend toward greater use of um vs. uh. That is the um:uh ratio is increasing.
I used the on-line corpora available at English-Corpora.org for this, specifically using the spoken portion of the COCA corpus as a baseline for spontaneous speech, and then the new TV and Movie corpora to represent simulated spontaneous speech. While the frequency rates in TV and Movie corpora are only about one-tenth the rate in COCA-spoken, indeed, the change over time is the same: Over several decades, the um:uh ratios in all three corpora have been increasing, with the TV and Movie corpora showing a slight lag relative to COCA-spoken. Hence, the TV and Movie trends seem to lag rather than lead the actual change. You can read the details of this in my paper here.
[Note: This post was written in September, 2020. However, in order to preserve the chronology of the blog, it has been dated to reflect when the described events actually took place.]