Showcasing Fluidity in Montreal at CALICO
This year's not even half gone and I've already made my second trip abroad. I went to Montreal City in Quebec, Canada to attend the CALICO annual conference (Computer-Assisted Language Instruction Consortium) to showcase and promote my Fluidity application, which I've already talked about before (here and here, for example).

The conference was actually my first, full-blown CALL (computer-assisted language learning) conference. I can't believe I've gone this long without attending one. Of course, I've been to numerous conferences where CALL and CALI are common topics, but this is the first fully exclusive conference on these topics for me.
There were several interesting talks, but one of the most interesting people I met was someone whose talk I could not attend because he and I were presenting at the same time. A few days before the conference, I was contacted by Thomas Kehoe of LanguageTwo.com. He said he wanted to hear about my Fluidity system, but because our presentations coincided, he wanted to arrange to meet at another time. So, we set up a time on the first day of the conference. I explained to him about Fluidity, but more interestingly, I could hear about his work with LanguageTwo.com. It is a speech perception and pronunciation training program that is not completely unlike Fluidity. Superficially, it's quite different because the aim is pronunciation training, while Fluidity's aim is real-time feedback on fluidity parameters. But underlyingly, the goals are quite similar: capture the acoustic signals of learners' speech and analyze it for certain acoustic features and discrepancies from what is expected. Thomas gave me a detailed demonstration of the LanguageTwo.com application and service, which is well ahead of where I am with Fluidity (which is not yet publicly released).
Thomas also said something I found interesting to think about. During our conversation we talked about people who have pathological speech dysfluencies (like Colin Firth's King George IV in The King's Speech). Thomas is of the opinion that the difficulty that these people face is cognitively comparable to the difficulty that a second language learner faces: They know what they want to say, but the words just aren't there to say it.
I can see the similarity, but I'm not so sure that cognitively we're talking about the same thing. The dysfluent person actually has the underlying linguistic knowledge and cannot access it while the language learner does not have that knowledge (or at best, they have an incomplete or fuzzy knowledge). Still, the parallel is interesting for some discussion and thought and may make a good musings post in the future.
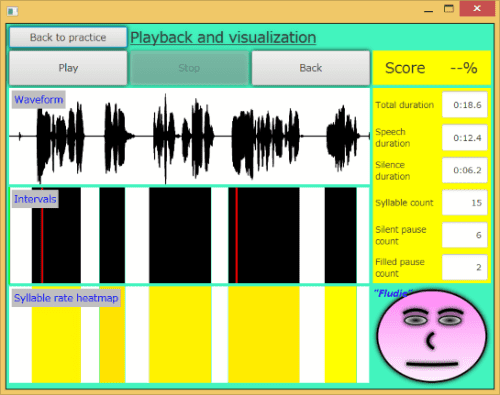
As for my presentation at CALICO, I participated in their "Technology Showcase" and gave a demonstration of Fluidity. The showcase itself was a very nice opportunity for researchers and developers like myself to present our work and systems to the CALICO attendees. But it did coincide with a kind of reception with food, drink, and chatter. Thus, it was a rather boisterous time with lots of background noise. This is most decidedly not the best atmosphere to demonstrate a speech detection application! Yet, I was pleasantly surprised that Fluidity did all right. It still managed to give modestly accurate results with speakers using a headset, even with unpredictable background noise. Software demonstrations at conferences are notoriously risky. So, I think I can count myself lucky this time.
Finally, let me share one interesting talk I heard by Dan Nickolai, Christina Garcia, and Lillian Jones. They are also interested in automated speech evaluation, focus on L2 pronunciation instruction and evaluation. They use automatic speech recognition (ASR) as a teaching tool and investigated how effective it was compared to instructor-based pronunciation training. Interestingly (but perhaps not surprisingly), results split as follows: For improving intelligibility, instructor-based practice is better; for fluency, ASR-only practice is better. This is a nice result, not least of which is because it means that there's hope for ASR in pronunciation training, but there's also little chance of it completely replacing the instructor (for now, at least!).
[Note: This post was written in September, 2020. However, in order to preserve the chronology of the blog, it has been dated to reflect when the described events actually took place.]