Learner Corpora in Louvain-la-Neuve
One of the acquaintances I was fortunate to make at the Fluency & Disfluency conference back in February this year was with several of the people who work and study at the Center for English Corpus Linguistics (CECL) at Université catholique de Louvain-la-Neuve (UCLouvain) in Belgium, about two hours south of Brussels. The (former) head of the center is Sylviane Granger, a well-known name in corpus linguistics and specifically learner corpora. So, I was quite please to have the chance to visit Louvain-la-Neuve again in October where I stayed for a couple of days. They arranged for me to give a research talk at the center, as well as an opportunity to give a lecture at a class in "Corpus Linguistics".

Because of the center's long history work on learner corpora, I spent most of my talk explaining about the Crosslinguistic Corpus of Hesitation Phenomena (CCHP). I particularly wanted to emphasize how the corpus gives us a unique view of the relationship between individual speakers' first and second language speech behavior. As I've argued elsewhere, this is useful because knowing how a speaker speaks in their first language provides a baseline for interpreting their second language speech performance. For example, if a speaker is a somewhat slow, deliberate speaker in their first language, then it should be no surprise if they also speak slowly in their second language. One wouldn't expect them to suddenly become a rapid-fire speaker.
However, it was at this point, that one interesting discussion arose. In talking about the above and in making that argument, I have occasionally quoted the following from a work by Yukio Tono:
"Very few learner corpora incorporate L1 data as an integral part of the design. This will become more important in future learner corpora projects as we are beginning to realise the need to identify specific features of L1-related errors or over/underuse patterns." (Tono 2003: 803)
I had been interpreting this as a call by him for L1 data from each individual. But Sylviane thought that Tono's meaning was somewhat less restrictive: that he was simply calling for the inclusion of generic L1 data—gathered under similar circumstances as the L2 data, but not necessarily from the same individuals. That's a fair point, and I see that I may have interpreted Tono's words a little too favorably to my position. Nevertheless, I don't think it undermines my basic reasoning in favor of the usefulness of having individual L1 data as baseline measures.
As for the main point of my talk, I emphasized that from the CCHP data, silent pause duration and filled pause rate are rather highly correlated between L1 and L2 speech, while articulation rate, silent pause rate, and repair rate show only low correlations. Thus, I argue that measures of second language development should not focus on silent pause duration and filled pause rate because any observations of them in L2 speech are simply reflections of their underlying L1 speech behavior.
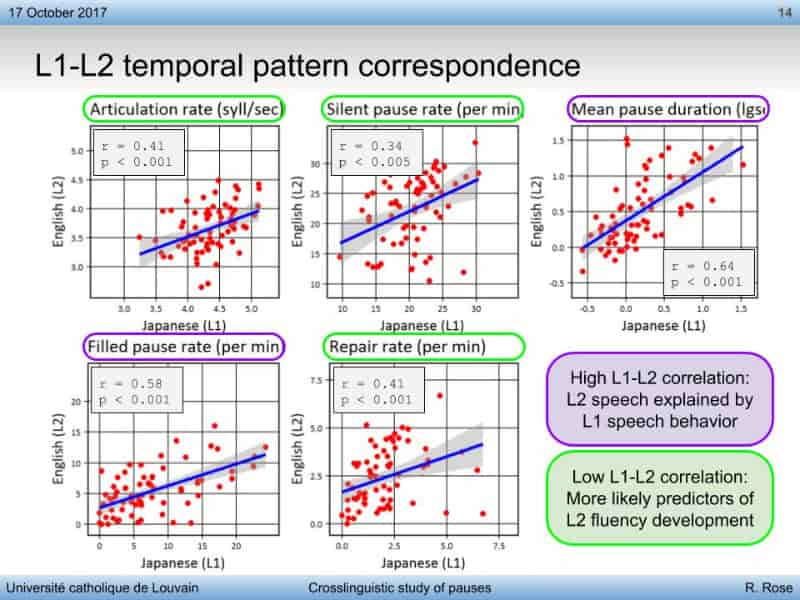
I repeated much of this talk to Gaëtanelle Gilquin's graduate-level "Corpus Linguistics" class. They were a great group of students and asked me several questions throughout the talk. It was clear, though, that they were still early in their careers as corpus linguists. I think so far, they had only imagined the use of corpus linguistics as—to some extent—an end in itself: that is, the output of a corpus linguistic effort as the answer to some research question. For me, though, corpus linguistics is largely a tool to generate questions or to inform experimental hypotheses or methods. I hope that they recognized how corpus linguistics is widely applicable across many research efforts.
Finally, I was treated to a fantastic lunch at a nearby restaurant. Belgian cuisine is certainly of a high grade. While I enjoyed every bite and count it as one of the best meals I've had in Europe, I worry if my amateur palate could fully appreciate its value.

[Note: This post was written in August, 2020. However, in order to preserve the chronology of the blog, it has been dated to reflect when the described events actually took place.]