Corpus linguistics, acoustic phonetics, and educational technology in Spain and Portugal
Whew! I took a trip in March to Spain and Portugal in which I really covered a lot of ground—both geographically and academically. The trip started with a jaunt to Malaga to attend CILC (International Conference on Corpus Linguistics). I presented some initial results on my PaLC project there (pauses and linguistic complexity). In short, I took some data from the Crosslinguistic Corpus of Hesitation Phenomena on English as a second language use of pauses compared to linguistic structure and then compared that to corresponding native English use of pauses from the Corpus of Presentations in English (COPE; by my colleague, Michiko Watanabe).

This was largely a preliminary analysis, but it is consistent with the idea that nonnatives gradually move toward the pausing patterns of native speakers. Both natives and nonnatives are more likely to use a filled pauses as an utterance grows longer. This is not an increase in rate, but rather position: As the utterance grows longer, the position(s) will be later. And that's not just because they are longer (a trivial result); rather the position is even later (proportionally speaking). So, it seems that the burden of producing a long utterance leads has an increased chance of leading to some latent disfluency.
CILC was also a busy time because my colleague Hinako Masuda and I reported on a pilot corpus project we have been working on called SELCor (Science and Engineering Learner Corpus)—a corpus intended to focus specifically on science and engineering students' productive skills in both speech and writing. It is only a pilot project to test the design and gathering procedure, but even with 13 participants, we could get some interesting—though not conclusive—results.
As another key feature of CILC, my colleague and good friend Laurence Anthony gave one of the keynote addresses, presenting and (successfully!) demonstrating his Twitter scraping application, FireAnt. Well done, Laurence!

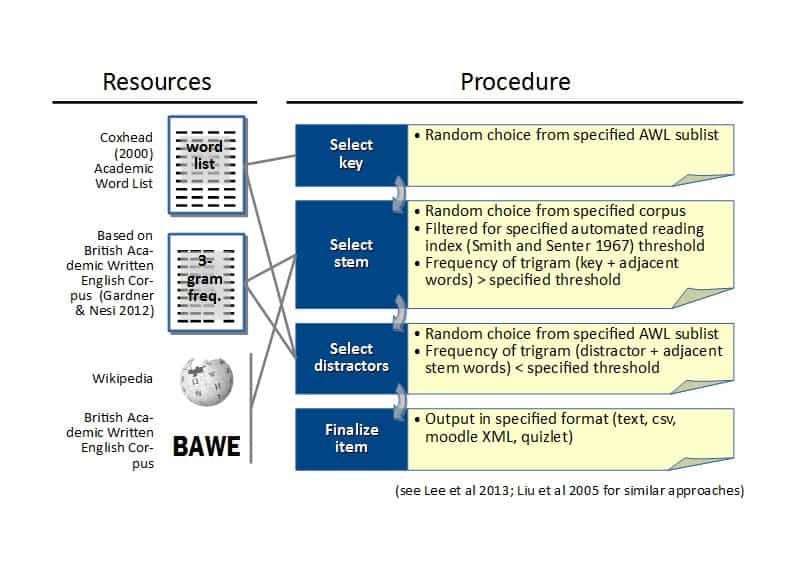
After Malaga, it was on to Valencia for INTED (International Technology, Education and Development conference) where I presented about my work on Word Quiz Constructor (WQC), an application I've been developing that is designed to create vocabulary quizzes automatically from online and offline corpus resources. I presented the results of a validation study I did on the vocabulary questions produced by WQC by asking Amazon Mechanical Turk workers to evaluate the questions as compared to a number of manually-produced items (by experienced professional teachers). Results showed that WQC items prepared in certain configurations (i.e., user-defined settings), are comparable to those produced manually.
The last leg of the trip was off to Lisbon where I visited the Spoken Language Research laboratory (L2F) at INESC-ID, affiliated with the Instituto Superio Technico and University of Lisbon. There I gave a colloquium talk about my corpus research and also presented about the Fluidity application that I have been developing. It was very well-received and I got some very helpful questions and feedback. One application that I learned of that day (which I had not known of before) was Duolingo. A little study since then reveals that Duolingo doesn't quite do what my application does, but it certainly is a broad-featured application otherwise. I may have to make use of it myself to learn a new language.
[Note: This post was written in August, 2020. However, in order to preserve the chronology of the blog, it has been dated to reflect when the described events actually took place.]